




Simple Examples of Downloading Files Using Python
Learn how you can download files from the web using various Python modules.
In this tutorial, you will learn how to download files from the web using different Python modules. Additionally, you will download regular files, web pages, YouTube videos, Google Drive files, Amazon S3, and other sources.
Lastly, you will learn how to overcome different kinds of challenges that you may encounter, such as downloading files that redirect, downloading large files, completing a multithreaded download, and other tactics.
Using Requests
You can download files from a URL using the requests module.
Consider the code below:
import requests
url = 'https://www.python.org/static/img/Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser. '
myfile = requests.get(url)
open('c:/users/LikeGeeks/downloads/PythonImage.png', 'wb').write(myfile.content)
Simply get the URL using the get method of requests module and store the result into a variable named "myfile." Then, you write the contents of the variable into a file.
Using wget
You can also download a file from a URL by using the wget module of Python. The wget module can be installed using pip as follows:
pip install wget
Consider the following code, which we will download the logo image of Python:
import wget
url = "https://www.python.org/static/img/Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser. "
wget.download(url, 'c:/users/LikeGeeks/downloads/pythonLogo.png')
In this code, the URL, along with the path (where the image will be stored), is passed to the download method of the wget module.
Download File That Redirects
In this section, you will learn to download from a URL, which redirects to another URL with a .pdf file using requests. The URL reads as follows:
https://readthedocs.org/projects/python-guide/downloads/pdf/latest/
To download this pdf file, use the following code:
import requests
url = 'https://readthedocs.org/projects/python-guide/downloads/pdf/latest/'
myfile = requests.get(url, allow_redirects=True)
open('c:/users/LikeGeeks/documents/hello.pdf', 'wb').write(myfile.content)
In this code, the first step we specify is the URL. Then, we use the get method of the request's module to fetch the URL. In the get method, we set the allow_redirects to True, which will allow redirection in the URL, and the content after redirection will be assigned to the variable myfile.
Finally, we open a file to write the fetched content.
Download Large File in Chunks
Consider the code below:
import requests
url = 'https://www.python.org/static/img/Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser. '
myfile = requests.get(url)
open('c:/users/LikeGeeks/downloads/PythonImage.png', 'wb').write(myfile.content)
First, we use the get method of the requests module as we did before, but this time, we will set the stream attribute to True.
Then, we create a file named PythonBook.pdf in the current working directory and open it for writing.
Then, we specify the chunk size that we want to download at a time. We have set to 1024 bytes, iterate through each chunk, and write the chunks in the file until the chunks finished.
The Python shell will look like the following when the chunks are downloading:
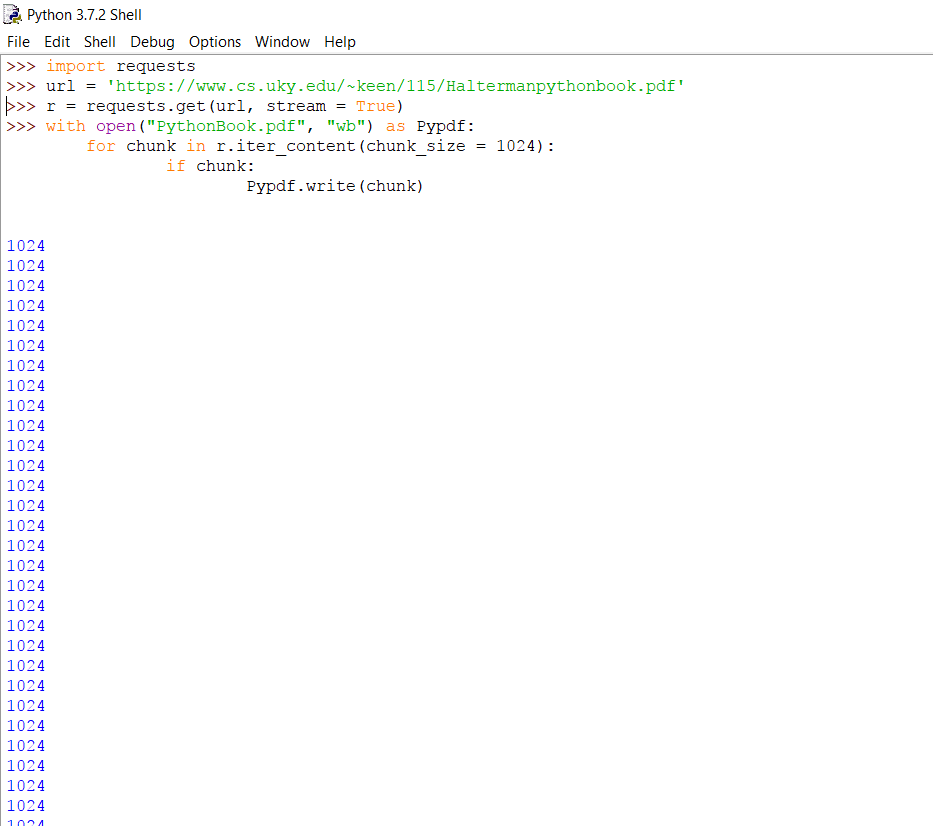
Not pretty? Don't worry, we will show a progress bar for the downloading process later.
Download Multiple Files (Parallel/Bulk Download)
To download multiple files at a time, import the following modules:
import os
import requests
from time import time
from multiprocessing.pool import ThreadPool
We imported the os and time modules to check how much time it takes to download files. The module ThreadPool lets you run multiple threads or processes using the pool.
Let's create a simple function that sends the response to a file in chunks:
def url_response(url):
path, url = url
r = requests.get(url, stream = True)
with open(path, 'wb') as f:
for ch in r:
f.write(ch)
The URLs is a two-dimensional array that specifies the path and the URL of a page you want to download.
urls = [("Event1", "https://www.python.org/events/python-events/805/"),
("Event2", "https://www.python.org/events/python-events/801/"),
("Event3", "https://www.python.org/events/python-events/790/"),
("Event4", "https://www.python.org/events/python-events/798/"),
("Event5", "https://www.python.org/events/python-events/807/"),
("Event6", "https://www.python.org/events/python-events/807/"),
("Event7", "https://www.python.org/events/python-events/757/"),
("Event8", "https://www.python.org/events/python-user-group/816/")]
Pass the URL to requests.get as we did in the previous section. Finally, open the file (path specified in the URL) and write the content of the page.
Now, we can call this function for each URL separately, and we can also call this function for all the URLs at the same time. Let's do it for each URL separately in for loop and notice the timer:
start = time()
for x in urls:
url_response (x)
print(f"Time to download: {time() - start}")
The result will be this:

Now, replace the for loop with the following line of code:
ThreadPool(9).imap_unordered(url_response, urls)
Run the script:

Download With a Progress Bar
The Progress bar is a UI widget of the client module. To install the client module, type the following command:
pip install clint
Consider the following code:
import requests
from clint.textui import progress
url = 'http://do1.dr-chuck.com/pythonlearn/EN_us/pythonlearn.pdf'
r = requests.get(url, stream=True)
with open("LearnPython.pdf", "wb") as Pypdf:
total_length = int(r.headers.get('content-length'))
for ch in progress.bar(r.iter_content(chunk_size = 2391975), expected_size=(total_length/1024) + 1):
if ch:
Pypdf.write(ch)
In this code, we imported the requests module, and then, from clint.textui, we imported the progress widget. The only difference is in the for loop. We used the bar method of progress module while writing the content into the file. The output will look like the following:
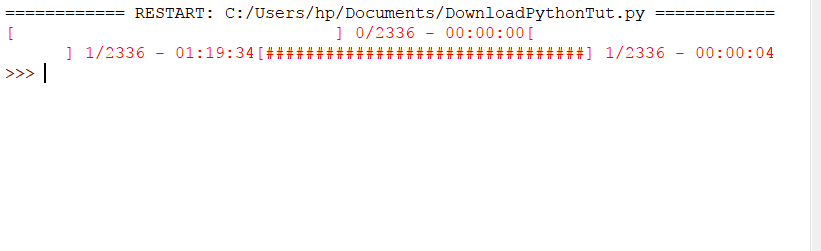
Download a Webpage Using urllib
In this section, we will be downloading a webpage using the urllib.
The urllib library is a standard library of Python, so you do not need to install it.
The following line of code can easily download a webpage:
urllib.request.urlretrieve('url', 'path')
Specify the URL here that you want to save as and where you want to store it:
urllib.request.urlretrieve('https://www.python.org/', 'c:/users/LikeGeeks/documents/PythonOrganization.html')
In this code, we used the urlretrieve method and passed the URL of a file, along with the path where we will save the file. The file extension will be .html.
Download via Proxy
If you need to use a proxy to download your files, you can use the ProxyHandler of the urllib module. Check the following code:
import urllib.request
>>> myProxy = urllib.request.ProxyHandler({'http': '127.0.0.2'})
>>> openProxy = urllib.request.build_opener(myProxy)
>>> urllib.request.urlretrieve('https://www.python.org/')
In this code, we created the proxy object and opened the proxy by invoking the build_opener method of urllib and passed the proxy object. Then, we made the request to retrieve the page.

Also, you can use the requests module as documented in the official documentation:
import requests
myProxy = { 'http': 'http://127.0.0.2:3001' }
requests.get("https://www.python.org/", proxies=myProxy)
Simply import the requests module and create your proxy object. Then, you can retrieve the file.

Using urllib3
The urllib3 is an improved version of the urllib module. You can download and install it using pip:
pip install urllib3
We will fetch a web page and store it in a text file by using urllib3.
Import the following modules:
import urllib3, shutil
The shutil module is used when working with files.
Now, initialize the URL string variable like this:
url = 'https://www.python.org/'
Then, we use the PoolManager of urllib3 that keeps track of necessary connection pools.
c = urllib3.PoolManager()
Create a file:
filename = "test.txt"
Finally, we send a GET request to fetch the URL and open a file and write the response into that file:
with c.request('GET', url, preload_content=False) as res, open(filename, 'wb') as out_file:
shutil.copyfileobj(res, out_file)
Download From Google Drive
You can use googledrivedownloader to download any file from Google Drive. To install it, use the following command:
pip install googledrivedownloader
Check out the code below:
from google_drive_downloader import GoogleDriveDownloader as gd
gd.download_file_from_google_drive(file_id='0B7XV2PwnZyfNalJ6cFd6dXBrckE',
dest_path='./data/2ndHalfJava.zip', unzip=True)
Here, we passed the file id of the Google drive file along with the destination path where we will save the file. Then, we have the unzip parameter. If it is True, the downloaded file will be unzipped in the same destination folder.

In this example, we download the zip folder, and then, the folder is unzipped.
Download File From S3 Using Boto3
To download files from Amazon S3, you can use the Python boto3 module.
Before getting started, you need to install the awscli module using pip:
pip install awscli
For AWS configuration, run the following command:
aws configure
Now, enter your details as:
AWS Access Key ID [None]: (The access key)
AWS Secret Access Key [None]: (Secret access key)
Default region name [None]: (Region)
Default output format [None]: (Json)
To download a file from Amazon S3, import boto3 and botocore. Boto3 is an Amazon SDK for Python to access Amazon web services such as S3. Botocore provides the command line services to interact with Amazon web services.
Botocore comes with awscli. To install boto3, run the following:
pip install boto3
Now, import these two modules:
import boto3, botocore
When downloading files from Amazon, we need three parameters:
- The name of Bucket
- The name of the file you need to download
- The name of the file after it has downloaded
Initialize the variables:
bucket = "bucketName"
file_name = "filename"
downloaded_file = "downloadedfilename"
Now, initialize a variable to use the resource of a session. For this, we will call the resource() method of boto3 and pass the service, which is s3:
service = boto3.resource(‘s3’)
Finally, download the file by using the download_file method and pass in the variables:
service.Bucket(bucket).download_file(file_name, downloaded_file)
Download Videos From Youtube
To download videos from YouTube, you can use the pytube module.
First, install the pytube module using pip as:
pip install pytube
Now, import YouTube from pytube as:
from pytube import YouTube
Then, pass the video URL you need to download:
YouTube('https://www.youtube.com/watch?v=himEMfYQJ1w').streams.first().download()
In this line of code, we passed the URL. Then, there are streams (list of formats) that the video has. For example:
streams = yt.streams.all()
>>> for x in streams:
print(x)
This will print all formats along with the video resolution as follows:
<Stream: itag="22" mime_type="video/mp4" res="720p" fps="30fps" vcodec="avc1.64001F" acodec="mp4a.40.2">
<Stream: itag="43" mime_type="video/webm" res="360p" fps="30fps" vcodec="vp8.0" acodec="vorbis">
<Stream: itag="18" mime_type="video/mp4" res="360p" fps="30fps" vcodec="avc1.42001E" acodec="mp4a.40.2">
<Stream: itag="36" mime_type="video/3gpp" res="240p" fps="30fps" vcodec="mp4v.20.3" acodec="mp4a.40.2">
<Stream: itag="17" mime_type="video/3gpp" res="144p" fps="30fps" vcodec="mp4v.20.3" acodec="mp4a.40.2">
<Stream: itag="136" mime_type="video/mp4" res="720p" fps="30fps" vcodec="avc1.4d401f">
<Stream: itag="135" mime_type="video/mp4" res="480p" fps="30fps" vcodec="avc1.4d4014">
<Stream: itag="134" mime_type="video/mp4" res="360p" fps="30fps" vcodec="avc1.4d401e">
<Stream: itag="133" mime_type="video/mp4" res="240p" fps="30fps" vcodec="avc1.4d400c">
<Stream: itag="160" mime_type="video/mp4" res="144p" fps="30fps" vcodec="avc1.4d400b">
<Stream: itag="140" mime_type="audio/mp4" abr="128kbps" acodec="mp4a.40.2">
The first() method grabs the first format and the download() method downloads the video.
If you want to fetch information about a video, for example, the title, then use .title as follows:
>>> video = YouTube('https://www.youtube.com/watch?v=himEMfYQJ1w')
>>> video.title
'Linux Environment Variables'
Using asyncio
The asyncio module is focused on handling system events. It works around an event loop that waits for an event to occur and then reacts to that event. The reaction can be calling another function. This process is called even handling. The asyncio module uses coroutines for event handling.
To use the asyncio event handling and coroutine functionality, we will import the asyncio module:
import asyncio
Now, define the asyncio coroutine method like this:
async def coroutine():
await my_func()
The keyword async tells that this is a native asyncio coroutine. Inside the body of the coroutine, we have the await keyword, which returns a certain value. The return keyword can also be used.
Now, let's create a code using a coroutine to download a file from the web:
>>> import os
>>> import urllib.request
>>> async def coroutine(url):
r = urllib.request.urlopen(url)
filename = "couroutine_downloads.txt"
with open(filename, 'wb') as f:
for ch in r:
f.write(ch)
print_msg = 'Successfully Downloaded'
return print_msg
>>> async def main_func(urls_to_download):
co = [coroutine(url) for url in urls_to_download]
downloaded, downloading = await asyncio.wait(co)
for i in downloaded:
print(i.result())
urls_to_download = ["https://www.python.org/events/python-events/801/",
"https://www.python.org/events/python-events/790/",
"https://www.python.org/events/python-user-group/816/",
"https://www.python.org/events/python-events/757/"]
>>> eventLoop = asyncio.get_event_loop()
>>> eventLoop.run_until_complete(main_func(urls_to_download))
In this code, we created an async coroutine function that downloads our files and returns a message.
Then, we have another async coroutine calls the main_func that waits for the URLs and makes a queue of all URLs. The wait function of asyncio waits for the coroutines to complete.
Now to start the coroutine, we have to put the coroutine inside the event loop by using the get_event_loop() method of asyncio, and finally, the event loop is executed using the run_until_complete() method of asyncio.
Downloading files using Python is fun. I hope you found this tutorial useful!
Source : https://dzone.com/articles/simple-examples-of-downloading-files-using-python